出于工作需求,要获取到足够多的网页数据给Hadoop研发人员做Demo用。自己简单试了试用NodeJS编写网络爬虫,初步感觉还不错,挺有意思。
准备工作
网络爬虫基本原理
这篇文章:网络爬虫基本原理(一)其实讲解地已经比较清楚了,尤其是那张图,在此引用一下:
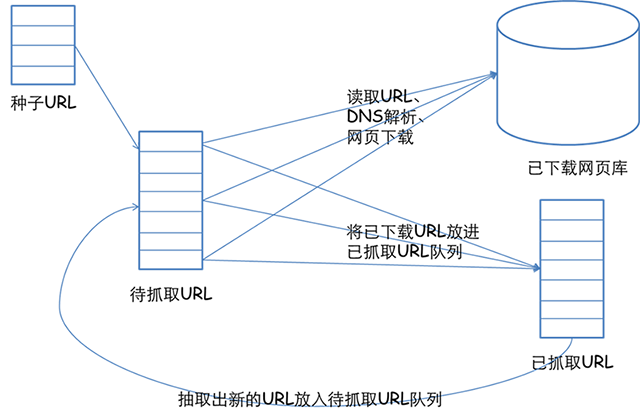
使用NodeJS写的网络爬虫已有不少示例(例如Create a simple web spider in node.js by Licson),思路大体一致,使用的包也大同小异,重点是要搞清楚:想从页面中获取什么?自己关心什么?然后要据此使用特定的正则表达式等词法分析手段。
安装爬虫程序的依赖包
主要安装的是两个模块:request模块、cheerio模块。前者用于发送HTTP请求,后者用于根据获取到的HTML数据创建一个DOM结构,从而可以对其进行类似jQuery的操作。
package.json文件内容如下:
package.json文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
| {
"name": "crawler",
"version": "0.0.1",
"private": true,
"author": "Wang Zilong",
"dependencies": {
"request": "~2.53.0",
"cheerio": "~0.18.0"
},
"engines": {
"node": "0.10.x",
"npm": "1.3.x"
}
}
|
小试牛刀
抓取豆瓣电影
下面的程序可以工作,使用的Node.js版本是 0.12.0。不过,对豆瓣请求过于频繁的话,它会对IP进行封禁。
该脚本以几个“种子URL”为入口,获取到一个页面后,先保存,然后解析该页面的HTML中具有相同结构的超链接(使用cheerio模块),对比已经检索过的页面的链接,如果不存在,则对其发起请求(基于request模块)。
程序段-01-豆瓣电影网页爬虫1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
| var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
var outStream = fs.WriteStream('urls.txt');
var originalURL = [
'http://movie.douban.com/subject/1292052/',
'http://movie.douban.com/subject/11026735/',
'http://movie.douban.com/subject/3993588/'
];
var urlDic = {};
var urlList = [];
var Tools = {};
Tools.getUrl = function(href){
var index = href.indexOf('?');
var url = href;
if (index > -1) {
url = href.substring(0, index);
}
return url;
};
Tools.getNumbersOfUrl = function(href){
var pattern = /\d+/;
var numbers = pattern.exec(href);
return numbers;
}
fetchNextURLs = function(url){
request({url: url}, function (error, response, body) {
if (error) {
return console.error(error);
}
console.log('成功爬取到页面: ' + url );
var $ = cheerio.load(response.body.toString());
var numbers = Tools.getNumbersOfUrl(url);
var htmlStream = fs.WriteStream('./douban_movies_html/movie'+numbers + '.html');
htmlStream.write(body);
htmlStream.end();
var hrefs = [];
$('#recommendations dt a').each(function(){
var $me = $(this);
var href = Tools.getUrl( $me.attr('href') );
var numbers = Tools.getNumbersOfUrl(href);
if(!urlDic[numbers]){
urlDic[numbers] = true;
hrefs.push(href);
outStream.write(href+ '\r\n');
}
});
if(hrefs.length === 0){
console.log('本页面未能爬取到新链接。');
}else{
urlList.concat(hrefs);
if(urlList.length< 100){
for (var i = 0; i < hrefs.length; i++) {
fetchNextURLs(hrefs[i]);
}
}else{
outStream.end();
console.log('超过预订的数目,爬虫程序正常结束。获取到的总链接数为:', urlList.length);
}
}
});
};
for (var i = 0; i < originalURL.length; i++) {
fetchNextURLs(originalURL[i]);
}
|
明确种子URL来源:利用网站提供的页面
有的站点实际上是自己提供种子URL的,例如京东商城的“全部分类列表”,点击其中任何一个分类(具有http://list.jd.com/listId.html格式),就可以得到一大批“优质”的链接(具有http://item.jd.com/id.html)。然后就可以利用类似上面的递归,来一个个获取页面。代码如下。
程序段-02-京东商城货品页网页爬虫1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
| var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
var outStream = fs.WriteStream('urls.txt');
var urlDic = {};
var urlList = [];
getSeeds = function(url){
request({url: url}, function (error, response, body){
if (error) {
return console.error(error);
}
console.log('得到种子页面: ' + url );
var $ = cheerio.load(response.body.toString());
$('a[href*="list.jd.com/"]').each(function(){
var $me = $(this);
var href = $me.attr('href');
fetchItemURLs(href);
});
});
};
fetchItemURLs = function(url){
request({url: url}, function (error, response, body) {
if (error) {
return console.error(error);
}
console.log('成功爬取到页面: ' + url );
var $ = cheerio.load(response.body.toString());
var pattern = /\d+-?\d+-?\d+/;
var numbers = pattern.exec(url);
var htmlStream = fs.WriteStream('./jd/item'+ numbers+'.html');
htmlStream.write(body);
htmlStream.end();
var hrefs = [];
$('a[href*="item.jd.com/"]').each(function(){
var $me = $(this);
var href = $me.attr('href');
var pattern = /\d+/;
var numbers = pattern.exec(href);
if(!urlDic[numbers]){
urlDic[numbers] = true;
hrefs.push(href);
outStream.write(href+ '\r\n');
}
});
if(hrefs.length === 0){
console.log('本页面未能爬取到新链接。');
}else{
urlList.concat(hrefs);
if(urlList.length< 1000){
for (var i = 0; i < hrefs.length; i++) {
fetchItemURLs(hrefs[i]);
}
}else{
outStream.end();
console.log('超过预订的数目,爬虫程序正常结束。获取到的总链接数为:', urlList.length);
}
}
});
};
getSeeds('http://www.jd.com/allSort.aspx');
|
添加请求头
京东的商品页面可以随便爬,不会对爬虫进行禁止(这也反映了该网站服务器集群性能的优异);但豆瓣就不一样了,我用2.1的程序爬之,获取了几百个页面,然后豆瓣就禁止该爬虫访问了。
解决的办法有:减小并发数;伪造成浏览器。后一个方法比较简单,如下。
1
2
3
4
5
6
7
8
9
10
| /* 给request的选项中添加 headers 属性,把User-Agent字段加入到每个HTTP请求的头部。
* 这样一来,豆瓣就会认为这是浏览器发起的一个请求从而不会拒绝响应了。
*/
request({
url: url,
headers: {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.99 Safari/537.36'
}
}, function (error, response, body) {
|
程序停止、数据保存
运行后会注意到,已经获取到的页面实际上已经远远超过预定值1000了,但是程序依旧没有停止下来。
大爷的,原来是对JS的Array concat函数理解错了。concat操作并不是在原数组的上面进行的,而是返回一个新的拼接后的数组。
另外,每当抓取到一个页面,就应该把该页面的 URL 保存到文件中,使用fs.appendFile()方法即可。
最后,将预期的抓取页面数作为程序的option属性的一部分,当达到该值后,便调用process.exit()方法立即结束当前的node程序(目前会导致最后一个正在搜索的结果不能保存下来,不过在总数目很可观的情况下,这无伤大雅)。
经过这一番折腾,针对豆瓣电影的爬虫变成这个样子:
程序段-03-豆瓣电影网页爬虫1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
| var fs = require('fs');
var request = require('request');
var cheerio = require('cheerio');
var originalURL = [
'http://movie.douban.com/subject/1292052/',
'http://movie.douban.com/subject/11026735/',
'http://movie.douban.com/subject/3993588/'
];
var option = {
targetNumber: 100000,
fileNames: {
crawled: 'urlCrawled.txt',
allURLsFound: 'allURLsFound.txt'
}
};
var urlDic = {};
var data = {
urlListAll: [],
urlListCrawled: [],
countUrlCrawled: 0
};
var Tools = {};
Tools.getUrl = function(href){
var index = href.indexOf('?');
var url = href;
if (index > -1) {
url = href.substring(0, index);
}
return url;
};
Tools.getNumbersOfUrl = function(href){
var pattern = /\d+/;
var numbers = pattern.exec(href);
return numbers;
}
Tools.saveCrawled = function(url){
data.countUrlCrawled++;
data.urlListCrawled.push(url);
fs.appendFile(option.fileNames.crawled, url + '\r\n', function (err) {
if (err) throw err;
});
};
Tools.exitCrawler = function(){
process.exit();
};
fetchNextURLs = function(url){
request({
url: url,
headers: {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.99 Safari/537.36'
}
}, function (error, response, body) {
if (error) {
return console.error(error);
}
Tools.saveCrawled(url);
console.log('成功爬取到页面: ' + url );
console.log('已爬页面数 = '+ data.countUrlCrawled );
var $ = cheerio.load(response.body.toString());
var numbers = Tools.getNumbersOfUrl(url);
var htmlStream = fs.WriteStream('./douban_movies_html/movie'+numbers + '.html');
htmlStream.write(body);
htmlStream.end();
var hrefs = [];
$('#recommendations dt a').each(function(){
var $me = $(this);
var href = Tools.getUrl( $me.attr('href') );
var numbers = Tools.getNumbersOfUrl(href);
if(!urlDic[numbers]){
urlDic[numbers] = true;
hrefs.push(href);
fs.appendFile(option.fileNames.allURLsFound, href+ '\r\n', function (err) {
if (err) throw err;
});
}
});
if(hrefs.length === 0){
console.log('本页面未能爬取到新链接。');
}else{
data.urlListAll = data.urlListAll.concat(hrefs);
if(data.countUrlCrawled < option.targetNumber){
for (var i = 0; i < hrefs.length; i++) {
fetchNextURLs(hrefs[i]);
}
}else{
console.log('爬取到的页面数目已达到预期值...');
Tools.exitCrawler();
}
}
});
};
for (var i = 0; i < originalURL.length; i++) {
fetchNextURLs(originalURL[i]);
}
|
读取之前的结果
如果在程序开始的时候,先读取之前已抓取的页面、待抓取的页面的列表,那么整个爬虫程序就变成了支持“断点续爬”功能的了。
【待完成】
关于遍历算法
在2、3小节中的两段代码,都是深度遍历优先的。
深度优先思路很简单,代码也容易写,但是存在致命的缺点:深度未知。因而就容易使爬虫陷进自己挖的坑里,即所谓“爬虫陷入问题”。