书名《JavaScript忍者秘籍》,作者呢是大名鼎鼎的 jQuery 的创作者。这本书里介绍了各种“忍者级”JS用法,收益颇丰。书中的许多示例代码体现了作者在设计 jQuery 时的编程思想,非常有价值。
第3章 函数是根基 函数的 name 属性,有别于函数表达式的变量名,它是函数声明时指定的。
第4章 挥舞函数 函数名是一个有趣的概念,它的本质是 token,与变量名、对象属性名一样,都有各自的可见范围。
函数声明可以使得该函数在其所在的词法作用域内在任意处访问到。
函数表达式里,如果 function 关键字后面带有函数名,那么该函数名字只能被自己的函数体内访问到,外部都不可见。
例如:
1 2 3 4 5 6 7 var a = function b() { console.log(b.name); }; a(); // b b(); // Uncaught ReferenceError: b is not defined
而且函数名是一个优先级比较弱的标识符,函数的形参名会在函数体内覆盖函数名:
1 2 3 4 var a = function b(b) { console.log(b.name); }; a(); // Uncaught TypeError: Cannot read property 'name' of undefined
而在将对象的属性指向一个函数时,如果将函数进行命名,那么其行为与函数表达式一样。这样的函数被称为内联命名函数。
72页的一段代码非常有趣,对象的方法可以调用数组原型方法,例如 Array.prototype.push.call(this, objectB),然后如果这个对象有个 length 属性,那么这个原型方法呢就会将 length 值加 1,并且给对象添加一个数字属性,对象通过 [index] 访问这个数字属性,就可以访问到刚刚添加的对象 objectB。
4.4 函数重载方式
重载函数是函数的一种特殊情况,为方便使用,C++允许在同一范围中声明几个功能类似的同名函数,但是这些同名函数的形式参数(指参数的个数、类型或者顺序)必须不同,也就是说用同一个运算符完成不同的运算功能。这就是重载函数。重载函数常用来实现功能类似而所处理的数据类型不同的问题。
——来自百度百科
这本书给出的 JS 实现函数重载的技术与C++不同,但是思路是一样的:根据形参来、直观地重载;充分利用闭包来保存函数链。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 /** * 用于给对象添加重载方法的方法 * @param {[type]} object [description] * @param {[type]} name [description] * @param {Function} fn [description] */ function addMethod(object, name, fn) { var old = object[name]; object[name] = function() { if (fn.length === arguments.length) { return fn.apply(this, arguments); } else if (Object.prototype.toString.call(old) === '[object Function]') { return old.apply(this, arguments); } }; } /** * 定义一个测试对象 */ var ninjas = { values: ['a', 'b', 'c'] }; /** * 第一个是不带任何参数的方法 */ addMethod(ninjas, 'find', function() { return this.values; }); /** * 第二个方法带有一个字符串参数 */ addMethod(ninjas, 'find', function(str) { return this.values.filter(item => (item === str)); }); console.log(ninjas.find()); // ["a", "b", "c"] console.log(ninjas.find('c')); // [c"]
Jhon Resig 自夸说:这是个绝佳的技巧,因为这些绑定函数实际上并没有存储于任何典型的数据结构中,而是在闭包里作为引用进行存储 。
的确很巧妙。
第5章 闭包
传统上来说,闭包是纯函数式编程语言的一个特性。让闭包跨越到主流语言的开发商尤其令人鼓舞,因为它们能够大大简化复杂的操作,所以很容易在一些 JavaScript 库以及其他高级代码库中找到闭包的使用。
【89页】倒数第二段其实有个错误,原文是:“第二点和第三点解释了为什么内部闭包可以访问到变量 tooLate,而外部闭包不行。”其实由于 var 关键字对变量的声明提升作用,两种“闭包”是都可以访问到 tooLate 这个标识符的。不同之处只是在于对其取右值时拿到的值不同而已。如果真的是访问不到这个变量,那么会报 ReferenceError (引用错误,这是一种运行时错误)。很明显,tooLate 的值为 undefined,与访问 tooLate 时抛出 ReferenceError 相比,还是有很大区别的。
第8章 驯服线程和定时器 同一个 interval 处理程序的多个实例不能同时进行排队。因此,setInterval 的有些回调可能就被废弃掉了。
减少同时使用的定时器的数量,将有助于解决这种问题(卡顿),这就是为什么所有现代动画引擎都使用一种称为中央定时器控制(central timer control)的技术。
一个完整的中央定时器控制示例代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 <!DOCTYPE html> <html> <head> <title>test timer control</title> <style type="text/css"> #box { position: relative; border: 1px solid #999; display: inline-block; height: 100px; width: 100px; } </style> </head> <body> <div id="box"></div> </body> </html> <script type="text/javascript"> var timers = { timerID: 0, timers: [], add: function(fn) { this.timers.push(fn); }, start: function() { if(this.timerID) return; (function runNext() { if(timers.timers.length > 0) { for (var i = 0; i < timers.timers.length; i++) { if(timers.timers[i]() === false) { timers.timers.splice(i,1); i--; } } timers.timerID = setTimeout(runNext, 0); } })(); }, stop: function() { clearTimeout(this.timerID); this.timerID = 0; } }; var box = document.getElementById("box"), x = 0, y = 20; timers.add(function() { box.style.left = x + "px"; if(++x > 50) return false; }); timers.add(function() { box.style.top = y + "px"; y += 1; if (y > 120) return false; }); timers.start(); </script>
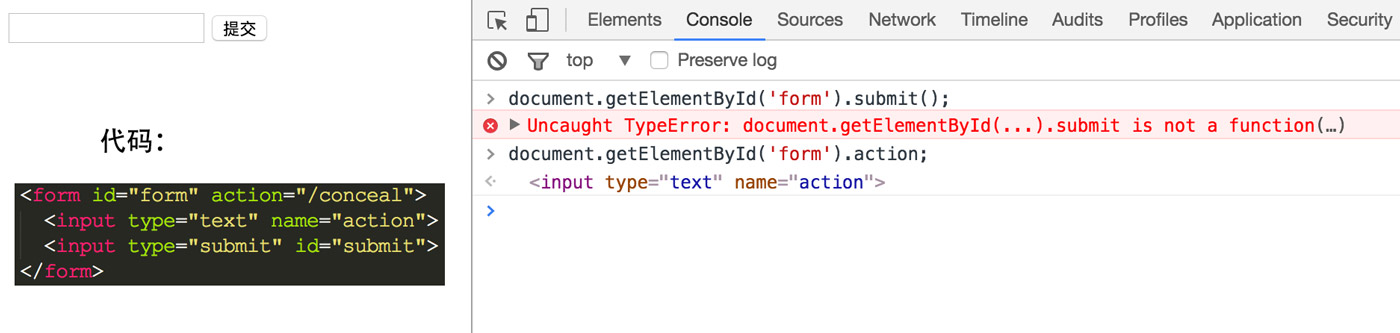
第 11 章 开发跨浏览器策略 这一章提到了一个概念,“贪婪ID复制”。例如下面的例子所示的:
第 12 章 洞悉特性、属性和样式 要知道,元素的 attribute(特性)与 property(属性)并非同一个东西。大多数时候相应的读写操作会有相同的结果,但也有例外。而且,二者在性能上也有较大的差别。属性操作往往要比特性操作快很多。
例如下面的性能测试代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 <!DOCTYPE html> <html> <body> <input type="text" id="test-1"> </body> <script type="text/javascript"> var NUM = 5000000; var input = document.getElementById('test-1'); var value; console.time('test-1'); for (var i = 0; i < NUM; i++) { value = input.getAttribute('value'); } console.timeEnd('test-1'); console.time('test-2'); for (var i = 0; i < NUM; i++) { value = input.value; } console.timeEnd('test-2'); </script> </html>
结果是:
test-1: 231ms
test-2: 117ms
差别非常明显。
另外一个例子是 URL 规范化。
1 2 3 4 5 6 <a href="test.html" id="test-subject">test</a> var link = document.getElementById('test-subject'); var linkHref_1 = link.getAttributeNode('href').nodeValue; // test.html var linkHref_2 = link.getAttribute('href'); // test.html var linkHref_3 = link.href; // file:///Users/wzl/Desktop/test.html
获取计算样式 广播一条API:
W3C标准API里有一个可以获得元素的计算样式的方法:window.getComputedStyle(element)。IE > 8 可用。
第 15 章 CSS 选择器引擎 15.1 W3C Selectors API 主要就是两个方法: querySelector() 和 querySelectorAll()。比较有趣的事情是这几个:
在今天来看,W3C Selectors API 其实已经有着非常好的浏览器覆盖率了。IE系列是“Partial support in IE8”,其他浏览器基本百分比支持。
这两个API都可以在 Document、documentFragment、Element 这三类 DOM 节点上面发起调用。发起调用的那个节点叫做 context node(The term context node refers to the node upon which the method was invoked. 参考 Selectors API Level 1 )。
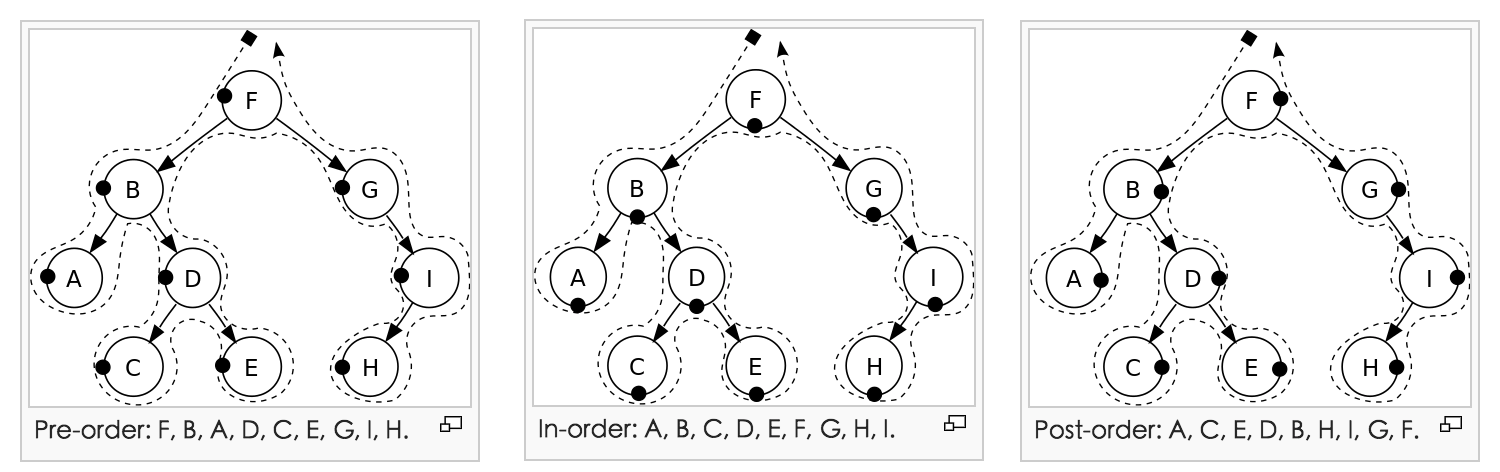
querySelector 返回的是第一个匹配的元素,querySelectorAll 返回的是所有匹配的元素组成的静态 NodeList。这里的为了找到“第一个”所采用遍历策略,是按照文档顺序(document order)进行查找匹配的。文档顺序是指“a depth-first pre-order traversal of the DOM tree or subtree in question”,即深度优先、先序遍历,这样可以与HTML文本的顺序一致。附:深度遍历的三种遍历图如下(参考:Tree Traversal | wiki pedia ):
有个小陷阱,下面的代码依然可以命中那个 strong 元素。这是因为对 querySelector/querySelectorAll 而言,无论指定 context node 为什么,其搜索总是从 document 根节点发起。只不过其返还结果里面会根据上下文节点进行过滤而已。
1 2 3 4 5 6 7 8 9 <body> <div id="test-selector"> <strong>strong text</strong> </div> <div>div</div> </body> var testDiv = document.getElementById('test-selector'); testDiv.querySelector('div strong'); // 可以命中那个 strong 元素